Fine-Tuning YOLOv8 for Real-Time Conveyor Belt Tracking
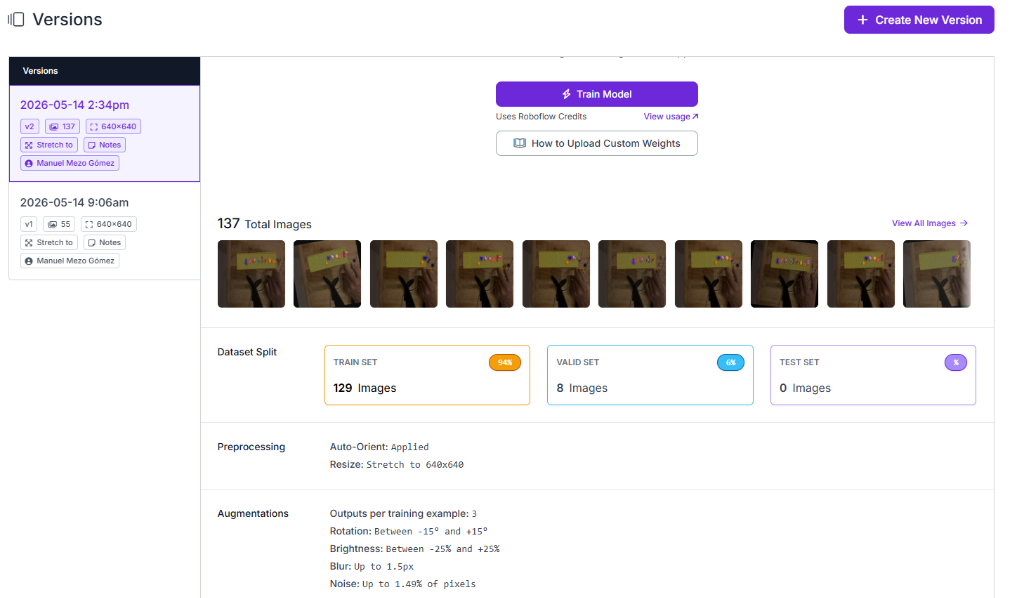
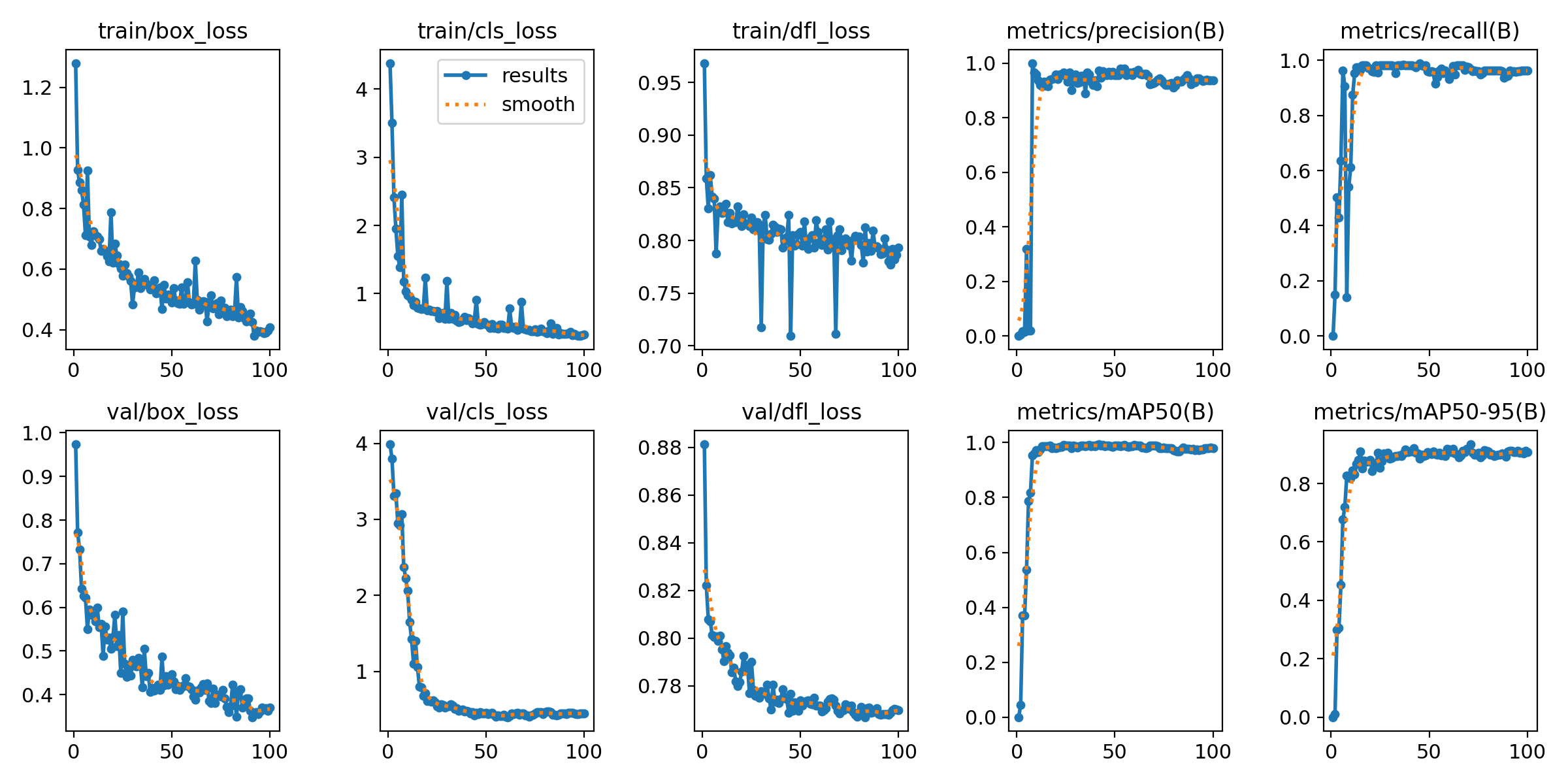
The end goal of this project is to feed a robotic arm: a vision system that can detect, classify, and track custom wooden objects moving on a physical conveyor belt, at real-time inference speeds, and with sufficient positional accuracy to guide pick-and-place operations. The conveyor belt system is fully 3D printed in PETG, utilizing a modular, open-source design from MakerWorld.
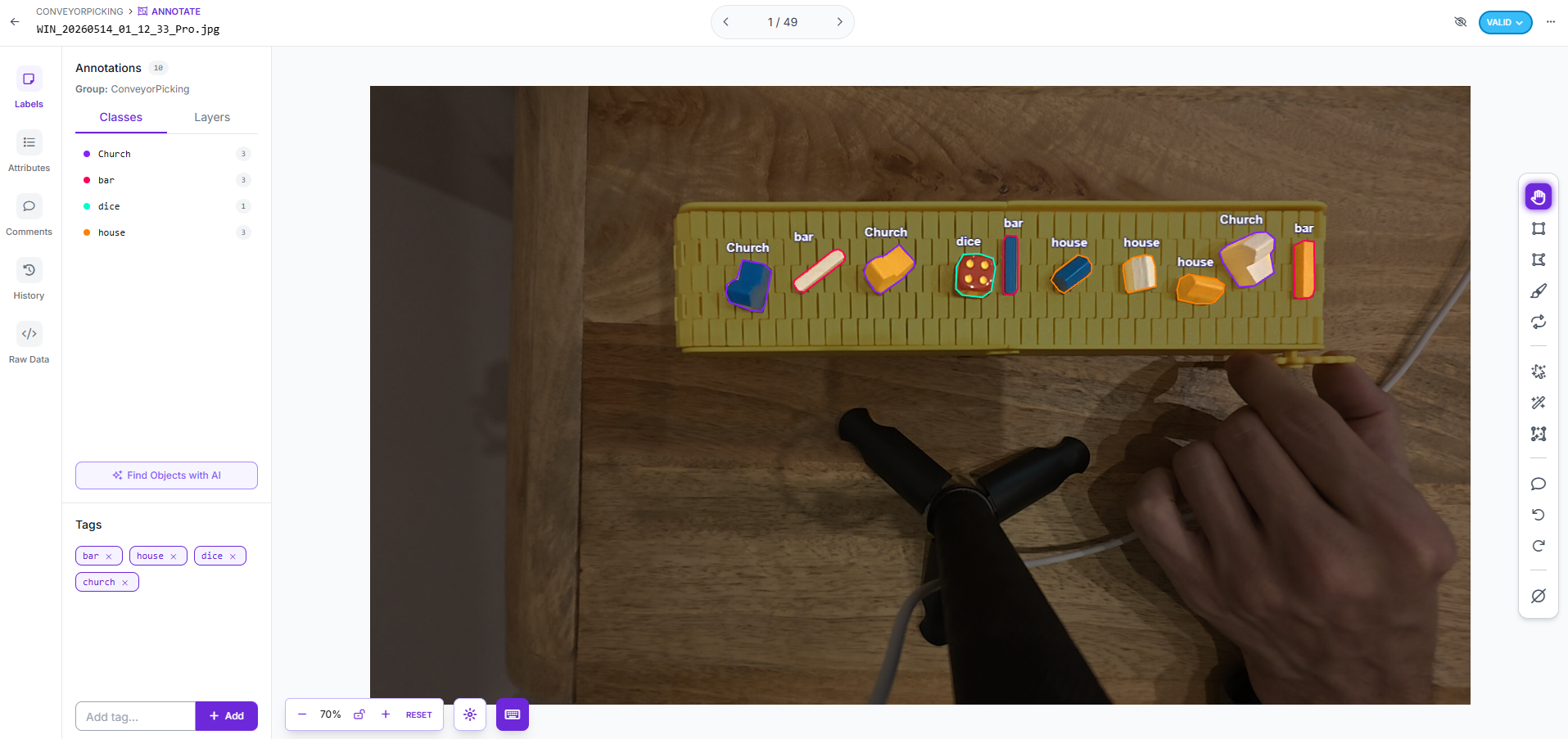
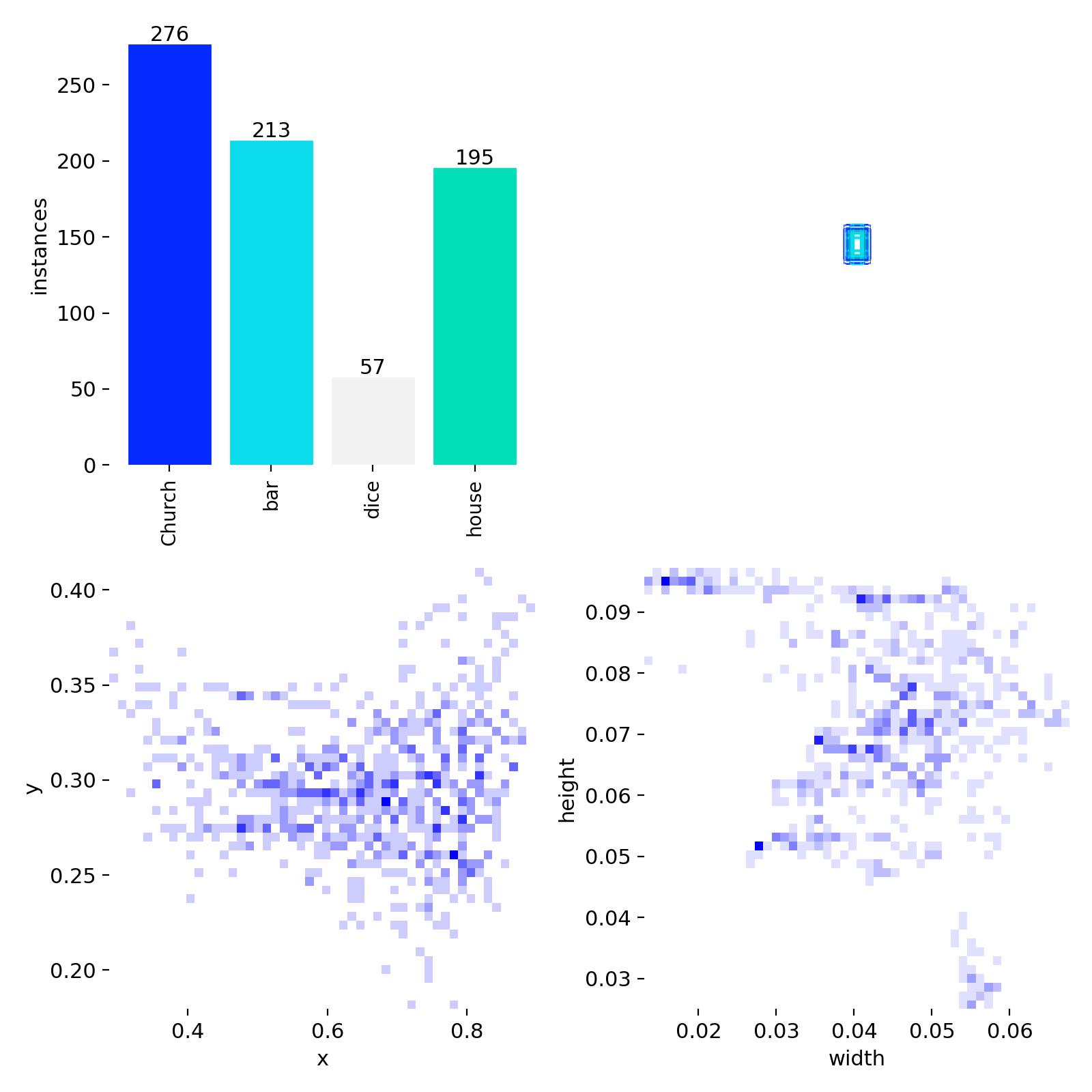
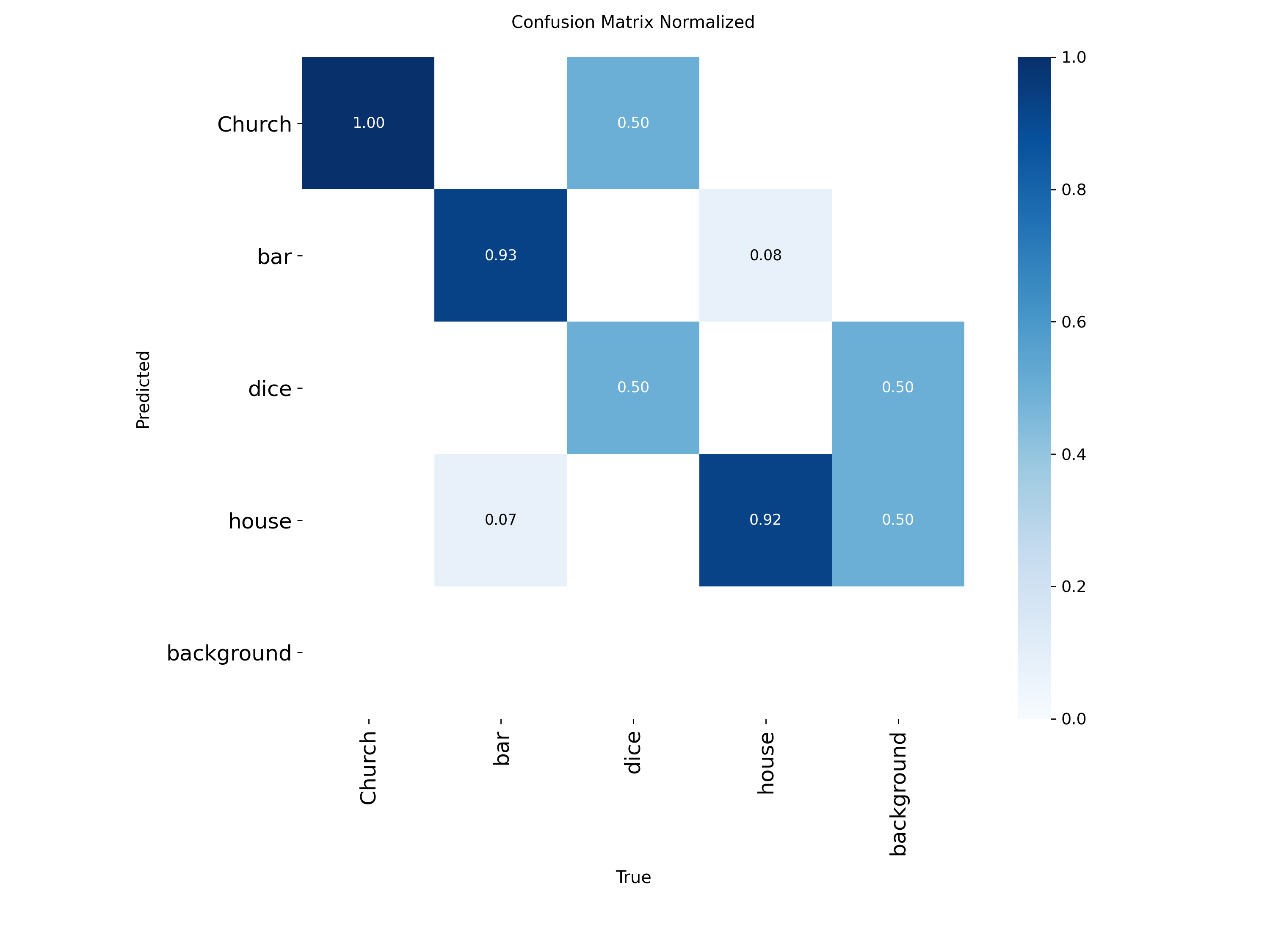
The target objects for recognition are the wooden game pieces from the Catan board game (see reference image below). These four custom object classes, Church, House, Bar, and Dice, are non-standard, small-scale, and visually similar in certain lighting conditions. No existing pre-trained model has ever seen them. This rules out any zero-shot approach and demands a purpose-built, fine-tuned model.

Reference: The Catan board game. The target wooden pieces (Church, House, Bar) are scattered across the board.